
Mengenal Perbedaan Crawling dan Indexing Google: Fondasi Visibilitas Online Anda
Dalam dunia digital yang serba cepat, memiliki website saja tidak cukup. Agar konten Anda dapat ditemukan oleh audiens yang tepat, website Anda harus terlebih dahulu terlihat oleh mesin pencari seperti Google. Proses ini, yang seringkali disalahpahami, melibatkan dua tahapan krusial: crawling dan indexing. Bagi para blogger, pemilik UMKM, freelancer, maupun digital marketer, Mengenal Perbedaan Crawling dan Indexing Google bukanlah sekadar pengetahuan teknis, melainkan fondasi esensial untuk strategi SEO yang berhasil.
Banyak pemilik website bertanya-tanya mengapa halaman mereka tidak muncul di hasil pencarian Google (SERP), padahal mereka merasa sudah mengoptimasi konten dengan baik. Seringkali, jawabannya terletak pada salah satu dari dua proses ini. Memahami bagaimana Google menemukan, memproses, dan menyimpan informasi dari miliaran halaman web adalah langkah pertama untuk memastikan konten Anda tidak hanya ada, tetapi juga dapat diakses oleh calon pengunjung.
Artikel ini akan mengupas tuntas perbedaan fundamental antara crawling dan indexing, mengapa keduanya sangat penting, bagaimana Google melaksanakannya, serta strategi praktis untuk mengoptimalkan kedua proses ini demi meningkatkan visibilitas website Anda.
Mengapa Memahami Crawling dan Indexing Sangat Penting untuk Website Anda?
Sebelum kita menyelami definisi masing-masing, mari kita pahami mengapa pengetahuan ini sangat krusial.
- Gerbang Menuju Visibilitas: Jika Google tidak bisa melakukan crawling atau indexing terhadap halaman Anda, maka halaman tersebut tidak akan pernah muncul di hasil pencarian. Sesederhana itu. Tanpa visibilitas, upaya pembuatan konten Anda akan sia-sia.
- Dasar dari SEO: Semua strategi Search Engine Optimization (SEO) dibangun di atas premis bahwa konten Anda dapat ditemukan dan dipahami oleh Google. Memahami proses ini membantu Anda merancang strategi SEO yang lebih efektif dan efisien.
- Kontrol Lebih Besar: Dengan memahami mekanisme crawling dan indexing, Anda memiliki kendali lebih besar atas bagaimana Google melihat dan memperlakukan website Anda. Anda bisa mengarahkan Googlebot ke halaman yang penting dan mencegahnya mengakses halaman yang tidak relevan.
- Diagnosa Masalah: Ketika website Anda mengalami masalah visibilitas, pemahaman tentang crawling dan indexing memungkinkan Anda mendiagnosis akar masalahnya dengan lebih akurat, apakah itu terkait dengan pemblokiran crawler atau masalah kualitas konten.
Memahami Proses Crawling: Penjelajah Web Google
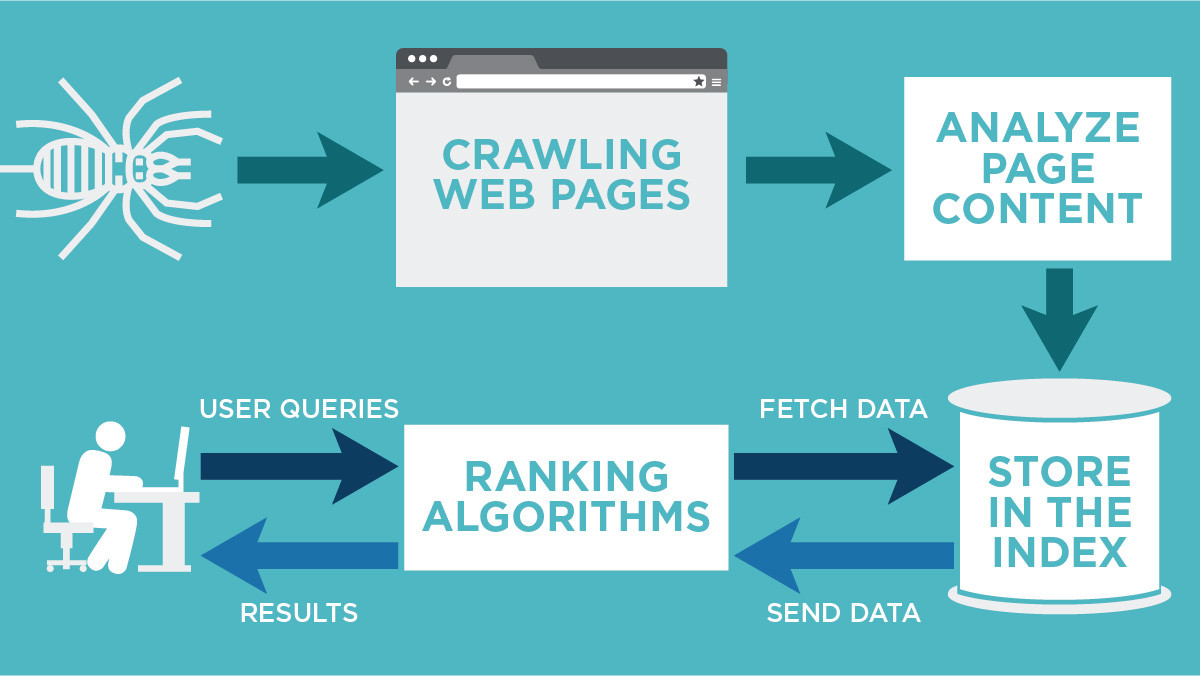
Crawling adalah tahap pertama dalam perjalanan sebuah halaman web untuk muncul di hasil pencarian Google. Ini adalah proses penemuan, di mana Googlebot (atau "spider" Google) menjelajahi internet untuk menemukan halaman web baru atau perubahan pada halaman yang sudah ada.
Apa Itu Crawling?
Secara sederhana, crawling adalah aktivitas penjelajahan web oleh robot mesin pencari. Googlebot berfungsi seperti pustakawan yang berkeliling di perpustakaan raksasa (internet) untuk mencari buku-buku baru atau edisi terbaru dari buku yang sudah ada. Tujuannya adalah untuk menemukan semua informasi yang tersedia di web.
Googlebot tidak hanya menemukan teks, tetapi juga gambar, video, CSS, JavaScript, dan semua elemen yang membentuk sebuah halaman web. Proses ini dilakukan secara otomatis dan terus-menerus, memastikan bahwa indeks Google selalu up-to-date dengan konten terbaru.
Bagaimana Googlebot Melakukan Crawl?
Proses crawling Googlebot tidak sembarangan. Ada beberapa cara dan faktor yang mempengaruhinya:
- Mulai dari URL Awal (Seed URLs): Google memiliki daftar URL awal yang sangat besar, yang sering disebut sebagai "seed URLs." Ini bisa berupa halaman yang sangat populer, situs otoritatif, atau URL yang baru disubmit melalui Google Search Console.
- Mengikuti Tautan (Link Following): Setelah Googlebot menemukan sebuah halaman, ia akan menganalisis semua tautan (internal dan eksternal) yang ada di halaman tersebut. Setiap tautan yang ditemukan akan ditambahkan ke antrean untuk dicrawl berikutnya. Inilah mengapa struktur tautan internal yang kuat sangat penting.
- Sitemap XML: Pemilik website dapat membuat file Sitemap XML, yang berfungsi sebagai "peta jalan" bagi Googlebot. Sitemap ini memberitahu Google halaman mana saja yang ada di situs Anda dan seberapa sering halaman tersebut diperbarui, membantu Googlebot menemukan konten yang mungkin terlewatkan.
- Permintaan Pengguna: Pengguna dapat meminta Google untuk melakukan crawl pada URL tertentu melalui Google Search Console, terutama untuk halaman baru atau halaman yang baru diperbarui secara signifikan.
Faktor-faktor yang Mempengaruhi Crawling
Beberapa elemen kunci dapat memengaruhi seberapa efisien Googlebot menjelajahi website Anda:
- File
robots.txt: Ini adalah file teks yang ditempatkan di root directory website Anda. Fungsinya adalah untuk memberitahu Googlebot bagian mana dari situs Anda yang boleh atau tidak boleh dicrawl. Penggunaan yang salah bisa secara tidak sengaja memblokir Googlebot dari halaman penting. - Struktur URL: URL yang bersih, logis, dan deskriptif lebih mudah dipahami dan diikuti oleh Googlebot.
- Internal Linking: Jaringan tautan internal yang kuat antar halaman membantu Googlebot menemukan semua halaman penting di situs Anda dan memahami hubungan antar topik.
- Sitemap XML: Seperti yang disebutkan, sitemap yang terstruktur dengan baik adalah alat vital untuk memandu Googlebot.
- Kecepatan Situs: Situs yang lambat dapat mengurangi "crawl budget" Anda. Googlebot mungkin tidak akan menghabiskan banyak waktu untuk menjelajahi situs yang membutuhkan waktu lama untuk memuat, sehingga beberapa halaman mungkin terlewatkan.
- Respons Server: Jika server Anda sering mengalami downtime atau responsnya lambat, Googlebot akan kesulitan mengakses halaman Anda.
- Kualitas Konten: Meskipun lebih berkaitan dengan indexing, konten berkualitas tinggi cenderung menarik lebih banyak tautan dari situs lain, yang pada gilirannya dapat meningkatkan frekuensi crawling.
Memahami Proses Indexing: Menyimpan dan Mengorganisir Informasi
Setelah Googlebot berhasil melakukan crawling pada sebuah halaman, tahap selanjutnya adalah indexing. Ini adalah proses di mana Google memproses informasi yang telah dicrawl, menganalisisnya, dan menyimpannya dalam database raksasanya.
Apa Itu Indexing?
Indexing adalah proses penyimpanan, pengorganisasian, dan penganalisisan konten yang telah ditemukan oleh Googlebot. Jika crawling adalah tentang menemukan buku-buku baru di perpustakaan, maka indexing adalah tentang membaca buku-buku tersebut, memahami isinya, mengkategorikannya, dan menambahkannya ke katalog perpustakaan agar mudah ditemukan di kemudian hari.
Hanya halaman yang berhasil diindeks oleh Google yang memiliki peluang untuk muncul di hasil pencarian. Jika sebuah halaman dicrawl tetapi tidak diindeks, itu berarti Google telah melihatnya tetapi memutuskan untuk tidak menyimpannya dalam "katalog" pencariannya.
Apa yang Dilakukan Google Selama Indexing?
Ketika Google melakukan indexing, ia tidak hanya sekadar menyimpan data mentah. Ada serangkaian analisis kompleks yang terjadi:
- Memproses Konten: Google menganalisis teks, gambar, video, dan semua elemen lain di halaman. Ini melibatkan pemahaman bahasa, identifikasi topik utama, dan ekstraksi kata kunci relevan.
- Menganalisis Kualitas dan Relevansi: Algoritma Google mengevaluasi kualitas konten, originalitasnya, dan seberapa relevan halaman tersebut dengan topik tertentu. Konten duplikat atau berkualitas rendah cenderung sulit diindeks.
- Menyimpan di Database: Informasi yang telah diproses disimpan dalam indeks Google, yang merupakan database terdistribusi raksasa. Database ini sangat terorganisir, memungkinkan Google mengambil informasi yang relevan dengan sangat cepat ketika ada pencarian.
- Memahami Konteks dan LSI: Google berusaha memahami konteks keseluruhan halaman dan bagaimana berbagai konsep saling terkait. Ini melibatkan penggunaan Latent Semantic Indexing (LSI) untuk mengidentifikasi kata kunci dan frasa terkait yang membantu Google memahami topik secara lebih mendalam.
- Mengevaluasi Sinyal Kualitas: Google juga menilai berbagai sinyal kualitas, seperti pengalaman pengguna (misalnya, Core Web Vitals), keramahan seluler (mobile-friendliness), dan otoritas situs (melalui backlink). Faktor-faktor ini memengaruhi peluang sebuah halaman untuk diindeks dan peringkatnya di kemudian hari.
Faktor-faktor yang Mempengaruhi Indexing
Beberapa faktor penting menentukan apakah halaman Anda akan diindeks atau tidak:
- Tag Meta
noindex: Ini adalah instruksi di dalam kode HTML halaman yang secara eksplisit memberitahu Google untuk tidak mengindeks halaman tersebut. Penggunaan yang tidak disengaja dapat menyebabkan halaman penting tidak muncul di SERP. - Kualitas dan Originalitas Konten: Google sangat menghargai konten yang unik, informatif, dan bernilai bagi pengguna. Konten tipis, duplikat, atau yang dijiplak sangat mungkin tidak diindeks.
- Mobile-Friendliness: Dengan mobile-first indexing, Google memprioritaskan versi seluler situs Anda. Jika situs Anda tidak responsif atau sulit digunakan di perangkat seluler, ini dapat menjadi hambatan besar untuk indexing.
- Kecepatan Situs: Meskipun juga memengaruhi crawling, kecepatan situs yang buruk dapat berdampak negatif pada pengalaman pengguna, yang merupakan sinyal kualitas penting bagi indexing dan ranking.
- Struktur Data (Schema Markup): Penggunaan markup schema yang tepat dapat membantu Google memahami konteks dan jenis konten Anda dengan lebih baik, meningkatkan peluang untuk diindeks dan bahkan muncul dalam rich snippets.
- Sinyal Otoritas dan Backlink: Halaman dari situs yang otoritatif dan memiliki banyak backlink berkualitas tinggi cenderung lebih mudah diindeks dan diberi prioritas oleh Google.
- Keterbaruan Konten: Konten yang sering diperbarui dan relevan cenderung lebih sering diindeks ulang dan dipertimbangkan lebih relevan.
Perbedaan Mendasar Antara Crawling dan Indexing
Untuk semakin Mengenal Perbedaan Crawling dan Indexing Google, mari kita simpulkan inti perbedaannya:
| Fitur | Crawling | Indexing |
|---|---|---|
| Tujuan Utama | Menemukan halaman baru atau perubahan | Memproses, menganalisis, dan menyimpan konten |
| Aktor | Googlebot (web crawler/spider) | Algoritma pemrosesan Google |
| Hasil | Daftar URL yang telah ditemukan | Konten yang disimpan dalam database Google |
| Analogi | Pustakawan mencari buku baru di rak | Pustakawan membaca, mengkategorikan, dan memasukkan buku ke katalog |
| Ketergantungan | Crawling harus terjadi sebelum indexing | Indexing hanya terjadi setelah crawling |
| Visibilitas | Halaman belum tentu muncul di SERP | Halaman memiliki potensi untuk muncul di SERP |
Penting untuk diingat bahwa crawling tidak menjamin indexing. Googlebot mungkin saja menjelajahi halaman Anda, tetapi jika halaman tersebut dianggap berkualitas rendah, duplikat, atau diblokir dengan noindex, maka halaman tersebut tidak akan diindeks dan tidak akan muncul di hasil pencarian.
Strategi Optimasi untuk Crawling dan Indexing yang Efektif
Setelah Mengenal Perbedaan Crawling dan Indexing Google secara mendalam, kini saatnya menerapkan strategi praktis. Mengoptimalkan kedua proses ini secara bersamaan adalah kunci untuk meningkatkan visibilitas website Anda.
Optimasi Crawling (Membantu Googlebot Menjelajah)
Tujuan optimasi crawling adalah mempermudah Googlebot menemukan dan mengakses semua halaman penting di situs Anda.
- Pastikan File
robots.txtBenar:- Periksa apakah ada perintah
Disallowyang tidak disengaja memblokir Googlebot dari halaman penting. - Gunakan Google Search Console untuk menguji
robots.txtAnda. - Blokir halaman yang tidak perlu dicrawl (misalnya, halaman admin, hasil pencarian internal) untuk menghemat crawl budget.
- Periksa apakah ada perintah
- Kirim dan Perbarui Sitemap XML:
- Buat sitemap XML yang akurat dan perbarui secara berkala.
- Kirim sitemap Anda melalui Google Search Console.
- Pastikan sitemap hanya berisi URL kanonis dan relevan yang ingin Anda indeks.
- Perbaiki Kecepatan Situs:
- Optimalkan gambar, gunakan caching, dan minimalkan file CSS/JavaScript.
- Pilih hosting yang cepat dan andal.
- Gunakan PageSpeed Insights untuk mengidentifikasi area perbaikan.
- Struktur URL yang Jelas dan Hierarkis:
- Gunakan URL yang pendek, deskriptif, dan mengandung kata kunci relevan.
- Hindari URL dengan banyak parameter yang tidak perlu.
- Contoh:
domain.com/kategori/nama-produklebih baik daripadadomain.com/p?id=123&cat=456.
- Bangun Internal Linking yang Kuat:
- Tautkan halaman yang relevan satu sama lain menggunakan anchor text yang deskriptif.
- Pastikan tidak ada halaman "yatim" (orphan pages) yang tidak ditautkan dari halaman lain.
- Gunakan breadcrumbs untuk navigasi yang lebih baik.
- Identifikasi dan Perbaiki Tautan Rusak (Broken Links):
- Tautan rusak (error 404) membuang crawl budget dan memberikan pengalaman buruk bagi pengguna.
- Gunakan alat seperti Google Search Console atau Screaming Frog untuk menemukan dan memperbaiki tautan rusak.
- Gunakan Tag Canonical yang Tepat:
- Untuk mengatasi masalah konten duplikat (misalnya, versi
httpdanhttps, atau halaman dengan parameter berbeda), gunakan tag<link rel="canonical" href="URL_versi_utama">untuk menunjukkan versi mana yang harus diindeks.
- Untuk mengatasi masalah konten duplikat (misalnya, versi
Optimasi Indexing (Memastikan Konten Disimpan dan Dipahami)
Tujuan optimasi indexing adalah memastikan Google tidak hanya melihat halaman Anda, tetapi juga memahaminya, menganggapnya berkualitas, dan menyimpannya dalam indeksnya.
- Konten Berkualitas Tinggi, Unik, dan Relevan:
- Buat konten yang informatif, mendalam, dan menjawab pertanyaan pengguna.
- Hindari konten yang tipis, generik, atau hasil jiplakan.
- Fokus pada user intent dan berikan nilai tambah yang unik.
- Gunakan Tag
noindexsecara Bijak:- Gunakan
noindexuntuk halaman yang tidak perlu muncul di SERP (misalnya, halaman kebijakan privasi yang tidak dioptimasi, halaman login, halaman arsip yang tidak relevan). - Pastikan halaman penting tidak sengaja diberi tag
noindex.
- Gunakan
- Prioritaskan Mobile-Friendliness:
- Desain situs Anda agar responsif dan mudah digunakan di semua perangkat.
- Gunakan Google’s Mobile-Friendly Test untuk memeriksa kompatibilitas.
- Pastikan konten utama dapat diakses di versi seluler.
- Perbaiki Core Web Vitals:
- Optimalkan Largest Contentful Paint (LCP), First Input Delay (FID), dan Cumulative Layout Shift (CLS) situs Anda.
- Ini adalah sinyal pengalaman pengguna yang penting bagi Google.
- Gunakan PageSpeed Insights dan laporan Core Web Vitals di Search Console.
- Implementasikan Struktur Data (Schema Markup):
- Gunakan schema.org markup (misalnya, untuk artikel, produk, resep, ulasan) untuk membantu Google memahami jenis konten Anda secara spesifik.
- Ini dapat menghasilkan rich snippets di SERP, meningkatkan visibilitas.
- Optimasi Gambar dan Media Lain:
- Gunakan atribut
alt textyang deskriptif untuk gambar. - Kompres gambar untuk kecepatan.
- Pastikan video memiliki transkrip atau deskripsi yang relevan.
- Gunakan atribut
- Bangun Backlink Berkualitas:
- Dapatkan tautan dari situs web yang relevan dan otoritatif.
- Backlink berkualitas tinggi adalah sinyal kepercayaan dan otoritas bagi Google.
- Fokus pada kualitas, bukan kuantitas.
- Perbarui Konten Secara Berkala:
- Konten yang segar dan diperbarui secara berkala cenderung lebih sering dicrawl dan diindeks ulang oleh Google, menunjukkan relevansi yang berkelanjutan.
Tools Penting untuk Memantau Crawling dan Indexing
Untuk memastikan upaya Anda membuahkan hasil, Anda perlu memantau kinerja crawling dan indexing website Anda.
- Google Search Console (GSC): Ini adalah alat yang paling penting dan wajib bagi setiap pemilik website.
- Laporan Cakupan (Coverage Report): Menunjukkan halaman mana yang diindeks, halaman mana yang memiliki masalah, dan alasan mengapa halaman tertentu tidak diindeks.
- Laporan Sitemap: Memantau status sitemap Anda, apakah berhasil diproses dan berapa banyak URL yang ditemukan.
- Laporan Statistik Crawl (Crawl Stats): Memberikan gambaran tentang aktivitas Googlebot di situs Anda, seperti jumlah permintaan crawl, waktu unduh rata-rata, dan respons server.
- Alat Inspeksi URL (URL Inspection Tool): Memungkinkan Anda memeriksa status crawling dan indexing URL tertentu secara real-time, meminta crawling, atau melihat versi Google dari halaman tersebut.
- PageSpeed Insights: Membantu menganalisis kecepatan situs dan Core Web Vitals, yang secara tidak langsung memengaruhi crawling dan indexing.
- Mobile-Friendly Test: Memeriksa apakah halaman Anda responsif dan mudah digunakan di perangkat seluler.
- robots.txt Tester (di GSC): Untuk menguji apakah file
robots.txtAnda memblokir Googlebot dari halaman yang seharusnya diakses. - Sitemap Validator: Alat online untuk memastikan format sitemap XML Anda benar dan bebas dari kesalahan.
Kesalahan Umum yang Perlu Dihindari
Bahkan dengan pemahaman yang baik tentang Mengenal Perbedaan Crawling dan Indexing Google, kesalahan umum masih sering terjadi.
- Memblokir Semua dengan
robots.txt: Kesalahan paling fatal adalah secara tidak sengaja memblokir seluruh situs atau bagian pentingnya dari Googlebot menggunakan filerobots.txt. - Menggunakan
noindexsecara Tidak Sengaja: Memberi tagnoindexpada halaman penting yang seharusnya muncul di hasil pencarian. Selalu periksa kode sumber halaman Anda. - Sitemap yang Tidak Valid atau Kadaluarsa: Sitemap yang berisi URL yang tidak ada, atau yang tidak diperbarui, dapat membingungkan Googlebot.
- Situs Sangat Lambat atau Server Sering Down: Ini akan sangat mengurangi crawl budget dan menghambat proses indexing.
- Konten Duplikat atau Berkualitas Rendah: Google akan enggan mengindeks konten yang tidak orisinal atau tidak memberikan nilai tambah.
- Tidak Memiliki Internal Linking yang Baik: Halaman "yatim" atau halaman yang sulit dijangkau melalui tautan internal akan sulit ditemukan oleh Googlebot.
- Mengabaikan Mobile-First Indexing: Dengan Google memprioritaskan versi seluler, situs yang tidak dioptimasi untuk seluler akan kesulitan diindeks dan diberi peringkat.
- Terlalu Bergantung pada JavaScript Tanpa Rendernya Optimal: Jika konten penting Anda hanya dimuat melalui JavaScript dan Googlebot kesulitan merendernya, konten tersebut mungkin tidak dicrawl atau diindeks.
Kesimpulan: Jalan Menuju Visibilitas Optimal di Google
Mengenal Perbedaan Crawling dan Indexing Google adalah langkah fundamental bagi siapa pun yang ingin sukses di dunia digital. Crawling adalah proses penemuan, di mana Googlebot menjelajahi web untuk mencari informasi baru. Indexing adalah proses di mana Google memproses, menganalisis, dan menyimpan informasi yang ditemukan dalam databasenya, menjadikannya tersedia untuk pencarian.
Kedua proses ini saling terkait erat, tetapi memiliki tujuan dan tantangan optimasinya masing-masing. Tanpa crawling, tidak akan ada indexing. Tanpa indexing, tidak akan ada visibilitas di hasil pencarian.
Dengan menerapkan praktik terbaik yang telah dijelaskan, mulai dari mengelola robots.txt dan sitemap, hingga memastikan konten berkualitas tinggi dan pengalaman pengguna yang optimal, Anda akan membangun fondasi yang kuat untuk visibilitas online Anda. Ingatlah, SEO adalah maraton, bukan sprint. Konsistensi dalam mengoptimalkan crawling dan indexing akan membawa hasil jangka panjang yang signifikan bagi website Anda. Mulailah memantau dan mengoptimasi situs Anda hari ini untuk membuka potensi penuh visibilitas di Google!





